The Cycle Everyone Notices
If you regularly use large language models like ChatGPT, Claude, or Gemini, you have likely noticed periods where the model's output quality inexplicably drops. You are not imagining this. We all see the cycle.
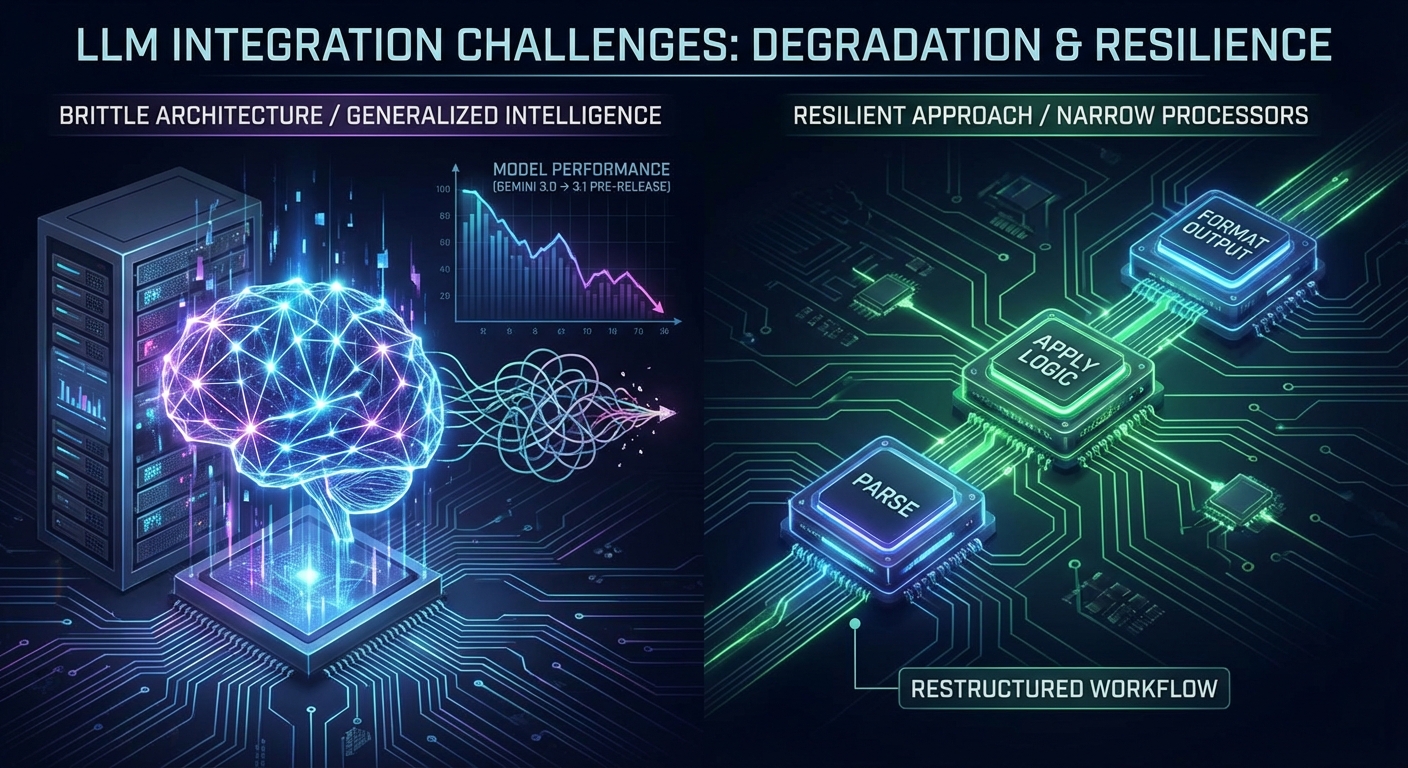
Remember when the Gemini 3.0 preview dropped? It was awesome. It wrote code like a senior developer and reasoned beautifully. But in the weeks right before the 3.1 Pro preview was released, it felt like it had survived a horrendous car accident and would never quite be the same again.
This phenomenon is a known variable in AI integration. A task that an LLM executed seamlessly on a Tuesday can unexpectedly send you into a hallucination triage spiral by Friday.
What We Saw at CMG
We documented this exact behavior while developing our proprietary ERP system. The platform relies on the Gemini API to perform large-scale data analysis. After establishing strict benchmarks – using static datasets, locked code, and finalized prompts – we noticed a measurable decline in output quality shortly before the release of Gemini 3.1. Nothing in our architecture had changed, but the model's ability to reason had degraded.
Why It Happens
The cause is typically server-side resource management. Prior to deploying a new frontier model, AI providers often quietly optimize their existing, public-facing models. They apply heavier quantization (compressing the model to save compute power) or alter safety alignment weights to free up infrastructure for the upcoming release.
As a result, the current model loses its edge, relying on shortcuts rather than deep reasoning. You cannot solve this degradation by simply writing a more emphatic prompt.
How We Fixed It
When our ERP benchmarks dropped, we resolved the issue by restructuring the underlying architecture. We broke the workflow down further, converting single, complex requests into a multi-step chain. By simplifying the prompts to require less reasoning at each individual stage, we reduced the cognitive load on the model and stabilized the outputs.
The Principle: LLMs Are Components, Not Infrastructure
This highlights a fundamental principle in commercial AI integration: the danger of relying on an LLM as a generalized intelligence.
The common instinct is to ask the model to parse data, apply business logic, and format the output all in a single request. However, this creates a highly brittle architecture. When the model's reasoning capacity fluctuates, the entire workflow fails.
The more resilient approach is to treat the LLM as a narrow processor. By isolating variables and confining the model to discrete, deterministic tasks, you insulate your systems from server-side shifts. The AI must be treated as a component of your software infrastructure, rather than the infrastructure itself.
Building for the Shift
Building reliable software on top of AI models requires constant benchmarking and the ability to restructure workflows when the underlying models inevitably shift.
If integrating LLM APIs into your business workflows is something you feel you need, but you don't have the time or the technical know-how to implement it, get in touch and we can help.